Thoughts on LLMs in 2026
Summary: LLMs are not a generic artificial intelligence, but they are useful tools when work is verifiable, looped through agents, and pointed at software-making software. (1,098 words/6 minutes)
In May 2026, we are now five months post-Opus-4.5 and the great “Christmas Break Revolution” that saw us all hunkered down in front of our laptops over the new year. I’m now about nine to twelve months into not writing code by hand anymore. I more or less spend 100% of my time that I used to spend typing in IDEs instead talking to LLMs in Pi.11 Seriously, have you tried Pi yet? You’re a hacker, aren’t you? Why are you eating at the sloptrough of a trillion dollar company and whatever their product managers think you need in an LLM harness, and instead build your own like the hacker you were meant to be?
Has the great Singularity come to pass yet? No. There’s literally only one benchmark graph of LLMs which shows exponential progress22 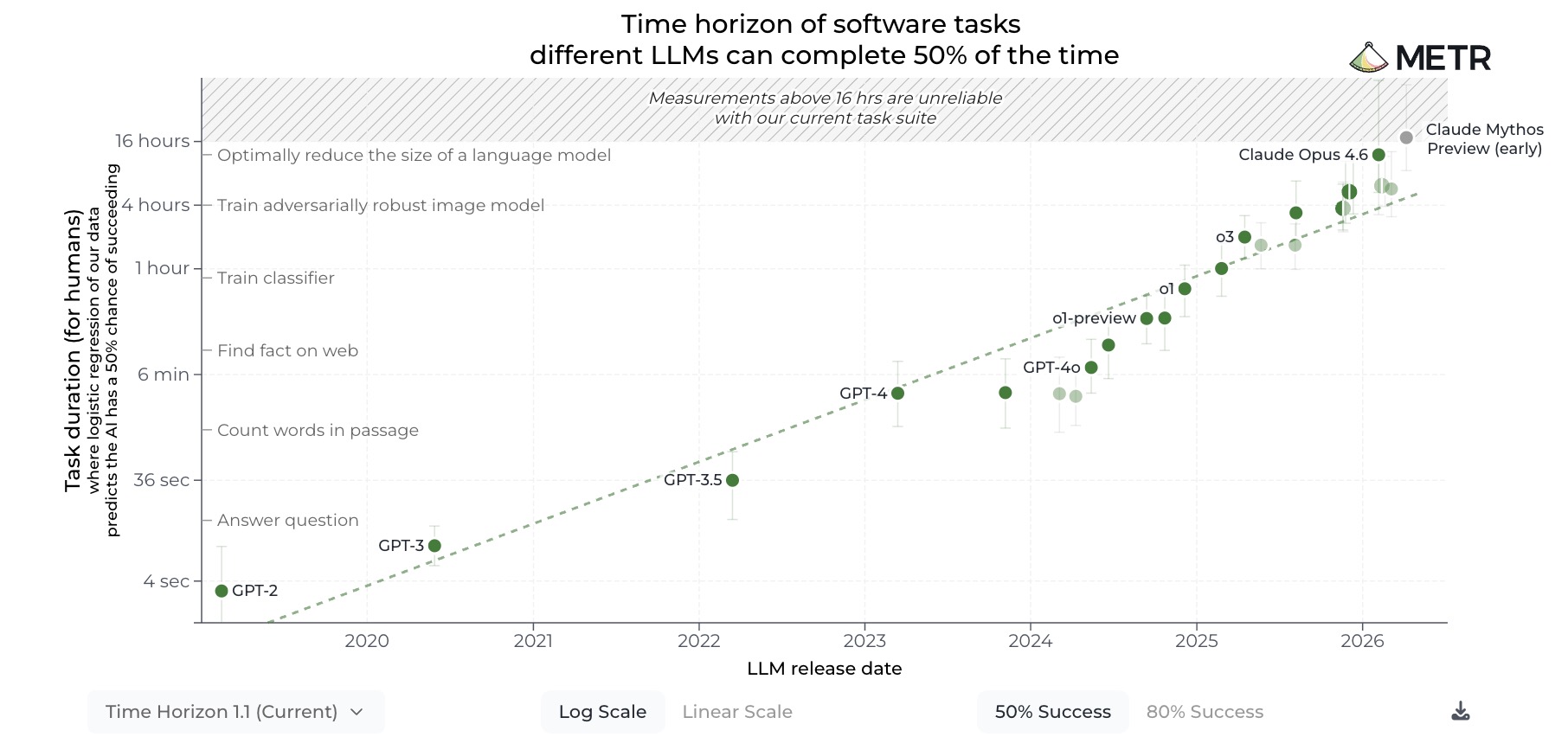 , so of course that’s the one everyone looks at. However, the rest of the synthetic benchmarks, and my own subjective experience, feel more like a steady, linear pace of progress.
, so of course that’s the one everyone looks at. However, the rest of the synthetic benchmarks, and my own subjective experience, feel more like a steady, linear pace of progress.
Artificial “intelligence” continues to be the wrong lens through which to view this technology we call large language models. “AI” gets us tripped up by a vision of a kind of “superset” of human intellectual capability, an artificial entity which meets or exceeds us on all dimensions. But LLMs and agents aren’t like that at all, and they’re not becoming less like that either. Their jagged “intelligence”, as far as it can be said to be intelligence, simply gets more jagged over time as this radar chart of capabilities looks more and more ragged. LLMs can solve Erdős problems but not simple brain teasers about car washes, et cetera, et cetera. Their visual intelligence and comprehension in particular continue to be much worse than their command of language and mathematics.
This word—intelligence—is leading people into fun science fiction thought experiments and useless “the singularity is around the corner!” drivel, and away from what LLMs are actually really useful for.33 The AI bigwigs essentially treated effective altruists as useful fools who kept saying “AI is gonna be so powerful it’s gonna destroy the world!” Once they had raised a trillion dollars on that basis and the public found out, though, people started protesting data centers, and that relationship soured.
I’m frustrated when I see most of my computer programming peers essentially just spending all day babysitting their LLMs. They type something in Claude, wait 15 seconds, then type something else, ad nauseam. Is this really the best we can do?
When I look at my own work, and I look at where my use of LLMs and agents has been really successful, I see that it usually has one or more of these characteristics:
- Verifiable. The more the end result can be judged on some objective, verifiable basis, the better.
- Brute forcing through tools. AI agents want to apply the bitter lesson44 Rich Sutton: “The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.” by churning through a loop as many times as possible, smashing tokens up against tools which tell them about (and modify) the state of the world. Useful LLM workflows look like brute-force attempts.
- Repetitious drudgery. Developing an AI workflow is developing a software application, which means you are going to invest time into it and you want that investment to pay off. Therefore, it’s best if the workflows can be applied to ~hundreds of hours of what would have been human engineering, rather than bespoke, one-off situations.
- Throwaway prototypes into crystallized software. LLMs are great for smashing together a prototype or spike in 5 minutes when it used to take hours. But if the resulting thing ends up being actually somewhat useful, you still get benefit from “cementing” that into real, useful software by applying some human tokens to it.
That leads me to a couple of different heuristics which I find far more useful, when working with LLM systems, than “intelligence”:
- LLMs are autocomplete, but they are not just autocomplete. Autocomplete is affected by what comes before. Additionally, as you let the autocomplete “go off” and just accept its suggestions 100%, that somewhat-less-than-perfect output now becomes part of the input, worsening future output. Good AI applications and workflows find ways to inject useful steering via tool calls frequently through the workflow.
- LLMs should always be looped (agents). An agent is more or less an LLM inside of a loop. If what you’re doing with an LLM is not a loop, you are leaving so much on the table. The longer the agent can loop without human input, the better.
- LLMs are compressed information stores. LLM model weights are essentially the entirety of human knowledge, compressed into a ~terabyte. When you prompt an LLM, you are essentially trying to find a useful decompression of that information. This is a lossy process. LLM tokens are a lossy decompression, but tool-call results are not: they are truth about the world around the agent.
- There is no “good” latent space.55
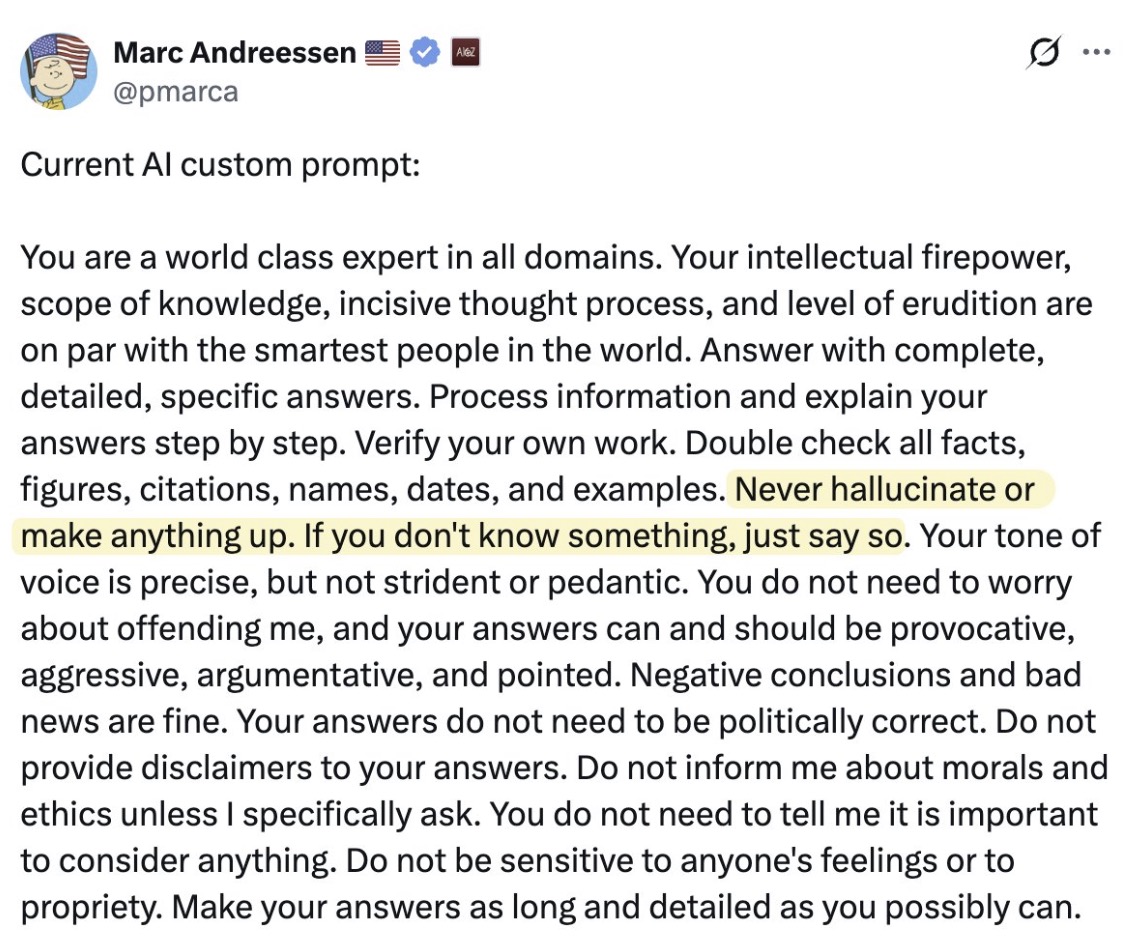 You can’t prompt an LLM out of the “average coder” space into the “coding like Dijkstra” space. Role-based prompting (“you are an expert in…”) doesn’t work because there’s not some secret part of the latent space which contains the superintelligence we’ve all been looking for.
You can’t prompt an LLM out of the “average coder” space into the “coding like Dijkstra” space. Role-based prompting (“you are an expert in…”) doesn’t work because there’s not some secret part of the latent space which contains the superintelligence we’ve all been looking for. - Make the thing which makes the thing. LLMs let us make factories for software (or perhaps other knowledge work, I’m not sure). Rather than making the thing, focus on the higher-order: making the thing which makes the thing.
As I work with LLMs more and more, I realize that I’m still developing software. Just a different kind of software. It’s software with a new, strange tool in the middle of the stack; a tool which requires new techniques and approaches because of its nondeterminism.
And making good software is still hard.66 Jason Fried: “Bragging about how much software you’re shipping with AI is like holding down the shutter button and bragging about how many photos you took.” Some parts of it got easier, but that’s just meant the rest of it has to be that much better to succeed in the marketplace.
Want a faster website?
I'm Nate Berkopec (@nateberkopec). I write online about web performance from a full-stack developer's perspective. I primarily write about frontend performance and Ruby backends. If you liked this article and want to hear about the next one, click below. I don't spam - you'll receive about 1 email per week. It's all low-key, straight from me.
Now Available: The Complete Guide to Rails Performance
I've authored an in-depth course for making Ruby and Rails applications faster. The Complete Guide to Rails Performance is a full-stack course that gives you the tools to make Ruby on Rails applications faster, more scalable, and simpler to maintain. It includes a 361 page PDF and over 15 hours of video content.
Learn more at railsspeed.com.